물리적 매체를 통해서 데이터 비트를 전송하기 위해 요구 되는 기능들을 정의하며 케이블 연결 장치 등 전송에 필요한 두 장치 간의 실제 접촉과 같은 기계적, 전기적 특성에 대한 규칙을 정의 한다.
전송 단위 : 프레임(Frame) 프로토콜 : 이더넷, MAC, PPP 등 장비 : 브릿지 스위치
데이터 링크 계층(Layer 2)
두 개의 개방 시스템들 간의 효율적이고 신뢰성 있는 정보 전송을 할 수 있도록 하며 오류의 검출과 회복을 위한 오류 제어 기능을 수행한다. 또한, 송신측과 수신측의 속도 차이를 해결하기 위해 흐름 제어(stop-and-wait & sliding window 방식으로 처리할 수 있는 패킷의 양보다 많은 경우) 기능을 하며 프레임의 시작과 끝을 구분하기 위한 프레임의 동기화 기능을 수행한다.
전송단위 : 프레임(Frame) 프로토콜 : 이더넷, MAC, PPP 등 장비 : 브릿지, 스위치
네트워크 계층(Layer 3)
다중 네트워크 링크에서 발신자로부터 목적지까지 책임을 가진다. 이전 계층인 데이터 계층은 노드 vs 노드 전달을 감독하는 것이고 네트워크 계층은 시작점에서 목적지까지 성공적으로 전달 되도록 하는 역할을 수행한다.
전송단위 : 패킷(Packet) 프로토콜 : IP, ICMP 등 장비 : 라우터, L3 스위치
전송 계층(Layer 4)
전체 메시지를 종단 vs 종단(End-to-End, 발신지에서 목적지)간 제어와 에러를 관리한다. 패킷의 전송이 유효한지 확인하고 전송에 실패된 패킷을 다시 보내는 것과 같은 신뢰성있는 통신을 보장한다. 주소 설정, 오류 및 흐름 제어, 다중화를 수행한다.
전송단위 : 세그먼트(Segment) 프로토콜 : TCP, UDP 등 장비 : 게이트웨이, L4 스위치
세션 계층(Layer 5)
양 끝단의 응용 프로세스가 통신을 관리하기 위한 방법을 제공한다. 동시송수신(Duplex), 반이중(Half-Duplex), 전이중(Full-Duplex) 방식의 통신과 함께 체크 포인팅과 유후, 종료, 다시 시작 과정 등을 수행한다. 통신 세션을 구성하며 포트 번호를 기반으로 연결한다.
프로토콜 : NetBIOS, SSH, TLS
표현 계층(Layer 6)
응용 계층으로부터 받은 데이터를 하위 계층인 세션 계층에 보내기 전에 통신에 적당한 형태로 변환하고 세션 계층에서 받은 데이터는 응용 계층에 맞게 변환하는 역할을 수행한다. 코드 변환, 구문 검색, 데이터 압축 및 암호화 등의 기능을 담당한다.
프로토콜 : JPG, MPEG, SMB, AFP
응용 계층(Layer 7)
응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행한다. 응용 프로세스 간의 정보 교환, 전자메일, 파일전송 등의 서비스를 제공한다.
프로토콜 : DNS, FTP, HTTP
HTTPS 프로토콜이란?
웹 브라우저와 웹서버 간에 메세지 교환 프로토콜. 즉, 일종의 대화 규칙이며, 교환 방식은 복잡한 바이너리 데이터가 아닌 단순 텍스트를 통해 이루어진다.
HTTP의 취약점(보안문제)을 보완하기 위해 주고받는 모든 메시지를 SSL 프로토콜로 암호화하며, 암호화 방식에 쓰이는 Key의 종류로는 크게 대칭과 비대칭 둘로 나뉘게 된다.
대표적인 웹 보안 취약점
1. 인젝션(Injection)
SQL 인젝션, OS 인젝션 등의 취약점은 신뢰할 수 없는 데이터가 서버로 전달되는 명령어의 일부로서 보내질 때 발생할 수 있다. 공격자의 악의적인 데이터는 예상하지 못하는 결과를 초래할 수 있다. 예를 들어 데이터베이스에서 회원 정보를 전부 가져오도록 인젝션을 날릴 수도 있다.
위의 만화에 대해 설명하자면, 저 학교에서 입력한 명령은 다음과 같을 것이다.
INSERT INTO students (이름) VALUES ('학생 이름');
여기서 "Robert'); DROP TABLE students;--"학생을 "학생 이름" 자리에 넣을 경우 다음과 같은 명령문이 된다.
INSERT INTO students (이름) VALUES ('Robert');DROP TABLE students;--');
첫 번째 줄에서는 Robert라는 학생이 입력되었지만, 두 번째 줄에서 학생들의 데이터가 있는 테이블을 제거한다. 그리고 세 번째에서는 뒤에 오는 내용을 모두 주석 처리한다. 결과적으로 ‘모든 학생 기록을 삭제한다.’라는 뜻의 명령문이 완성된다.
인젝션 공격 같은 경우는 공격 난이도가 낮은 데 반해서 공격 피해가 심각하다는 점에서 굉장히 중요하다.
2. 인증 및 세션관리 취약점
인증이나 세션 관리가 제대로 되어 있지 않은 웹 애플리케이션의 경우 공격자에게 취약한 세션 값을 제공하여 다른 사람의 권한을 얻도록 할 수 있다. 예를 들어 인증 관리에서 실수를 하여 쿠키 값을 변조했더니 다른 사람의 아이디로 로그인이 되거나 하는 경우가 실제로도 비일비재한다. 다른 사용자의 권한을 얻을 수 있다는 점에서 개인 정보 등의 측면에서 굉장히 위협적인 공격이 될 수 있다.
다음의 사례가 대표적인 취약점 사례이다.
사용자 인증 정보가 저장될 때 해시 혹은 암호화를 사용하여 보호되지 않을 때
세션 ID가 성공적인 로그인 이후에 교체되지 않을 때
아이디, 비밀번호, 세션 ID 등이 암호화되지 않은 연결을 통해서 전송될 때
세션 ID가 URL에 노출될 때
예를 들어 URL에 자신의 세션 ID가 그대로 노출되어 있는 상황이지만 클라이언트는 이를 인지하지 못하고 친구에게 해당 URL 정보를 보낼 수 있습니다. 이 때 친구는 URL을 확인하고 해당 세션으로 로그인을 할 수도 있는 것이다.
공격의 난이도는 평균적인 수준이지만 영향도는 인젝션(Injection) 공격과 마찬가지로 심각한 수준에 이른다.
3. 크로스 사이트 스크립팅(XSS)
XSS 공격은 웹 사이트에서 서버와 통신하는 부분에서 스크립트 문장을 심어서 공격을 하는 해킹 유형이다. 대표적으로 게시판의 게시글을 작성했을 때 서버 단에서 사용자가 입력한 게시글의 정보를 제대로 필터링 하지 않거나 아예 필터링을 하지 않는 경우 다양한 특수 문자를 포함한 스크립트 문장을 심어서 서버로 전송할 수 있다. 이러한 방법을 악용하여 다양한 공격이 가능하다.
기존의 웹브라우저는 전자 문서를 염두에 두고 고안된 시스템이기 때문에 내용이 바뀌면 페이지 새로고침을 해서 내용을 새롭게 변경해야 되는 정적인 시스템이였다.
그러다 Ajax 개념이 도입되면서 모든 것이 바뀌었다. Ajax는 웹브라우저와 웹서버가 내부적으로 데이터 통신을 하게 된다. 그리고 변경된 결과를 웹페이지에 프로그래밍적으로 반영함으로써 웹페이지의 로딩 없이 서비스를 사용할 수 있게 한다.
Ajax는 Asynchronous JavaScript and XML의 약자다. 한국어로는 비동기적 자바스크립트와 XML 정도로 직역할 수 있는데 자바스크립트를 이용해서 비동기적으로 서버와 브라우저가 데이터를 주고 받는 방식을 의미한다. 이 때 사용하는 API가 XMLHttpRequest이다. 그렇다고 꼭 XML을 사용해서 통신해야 하는 것은 아니다. 사실 XML 보다는 JSON을 더 많이 사용한다.
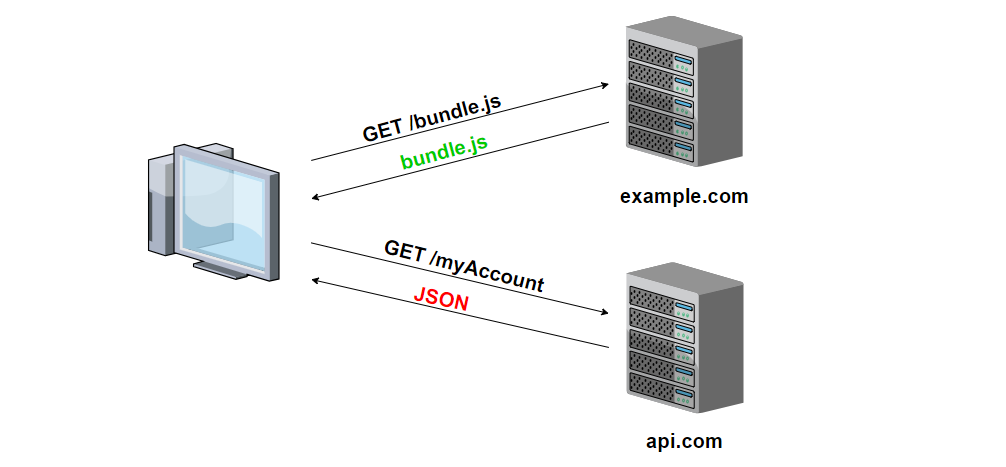
HTTP 프로토콜이란?
인터넷상에서 데이터를 주고 받기 위한 서버/클라이언트 모델을 따르는 프로토콜(상호 간에 정의한 규칙)이다.
데이터를 주고 받기 위한 각각의 데이터 요청이 서로 독립적으로 관리가 된다. 즉 이전 데이터 요청과 다음 데이터 요청이 서로 관련이 없다.
이러한 특징 덕택에 서버는 세션과 같은 별도의 추가 정보를 관리하지 않아도 되고, 다수의 요청 처리 및 서버의 부하를 줄일 수 있는 성능 상의 이점이 생긴다.
HTTP 프로토콜은 일반적으로 TCP/IP 통신 위에서 동작하며 기본 포트는 80번이다.
HTTP 접근 제어(CORS)란?
CORS는 무엇인가?
다른 도메인으로부터 요청될 경우, 일반적인 HTTP 요청이 아닌 cross-origin HTTP 요청으로 처리하게 된다.
브라우저는 보안상의 이유로 cross-origin HTTP 요청을 제한하게 된다.
이유는 단순히 same-origin 정책이다.
이러한 불편함으로 인해, 시간이 지나 W3C에서 대안으로 CORS 메커니즘을 내놓은 것이다.
CORS는 어떻게 동작되는 건가?
CORS는 라이브러리 혹은 구현 기술이 아닌 방침이라고 보면된다.
CORS는 브라우저의 정보를 읽을 수 있도록 서버에게 알려주도록 허용하는 HTTP 헤더를 추가함으로써 동작한다.
RESTful 설계란?
REST가 무엇인가?
REST는 분산 시스템 설계를 위한 아키텍처 스타일이다.
아키텍처 스타일이라는건 쉽게 말하면 제약 조건의 집합이라고 보면 된다.
REST는 URI를 통해 자원을 표시하고, HTTP METHO를 이용하여 해당 자원의 행위를 정해주며 그 결과를 받는 것을 말한다.
RESTful은 무엇인가?
RESTful은 위의 제약 조건의 집합(아키텍처 스타일, 아키텍처 원칙)을 모두 만족하는 것을 의미한다.
REST라는 아키텍처 스타일이 있는거고 RESTful API라는 말은 REST 아키텍처 원칙을 모두 만족하는 API라는 뜻이다.
SQL Subquery란?
쿼리 안에 있는 쿼리. Where/From/Select 절 안에 들어가는 쿼리.
서브쿼리는 하나의 쿼리문 안에 포함된 또 하나의 쿼리문으로(중첩문) 메인쿼리가 서브쿼리를 포함하는 종속적 관계
문법은 서브쿼리를 괄호로 묶어서 사용한다.
Order By절은 사용불가하며 연산자 오른쪽에 사용해야 한다.
서브쿼리의 반환값에 따른 서브쿼리
단일 행 서브쿼리 : 서브쿼리의 결과가 1행
다중 행 서브쿼리 : 서브쿼리의 결과가 여러 행
다중 컬럼 서브쿼리 : 서브쿼리의 결과가 여러 컬럼
SQL Join의 종류
두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색한다.
보통 primary key 혹은 Foreign key로 두 테이블을 연결한다.
연결하려면 적어도 하나의 컬럼은 서로 공유 되고 있어야한다.
1) 이너 조인(Inner Join)
교집합. 기존 테이블과 조인한 테이블의 중복 값을 보여주는데 결과값은 교집합만 검색
Sele
ct <별칭.칼럼>, <별칭.칼럼> From <기준테이블 별칭> Inner Join <조인테이블 별칭> On <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키> And <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키> 예) Select A.NAME, B.AGE From EX_TABLE A Inner Join JOIN_TABLE B On A.NO_EMP = B.NO_EMP And A.NO_DEPT = B.NO_DEPT
Select <별칭.칼럼>, <별칭.칼럼> From <기준테이블 별칭>
Inner Join <조인테이블 별칭>
On <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키>
And <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키>
예)
Select
A.NAME, B.AGE From EX_TABLE A
Inner Join JOIN_TABLE B
On A.NO_EMP = B.NO_EMP
And A.NO_DEPT = B.NO_DEPT
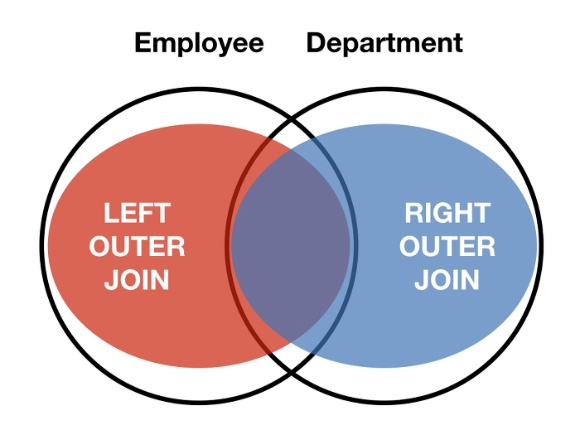
2) 아우터 조인(Left/Right Outer Join)
기존 테이블 값 + 교집합
Select <별칭.칼럼>, <별칭.칼럼> From <기준테이블 별칭> Left Outer Join <조인테이블 별칭> On <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키> And <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키> 예) Select A.NAME, B.AGE From EX_TABLE A Left Outer Join JOIN_TABLE B On A.NO_EMP = B.NO_EMP And A.NO_DEPT = B.NO_DEPT
Select <별칭.칼럼>, <별칭.칼럼> From <기준테이블 별칭>
Left Outer Join <조인테이블 별칭>
On <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키>
And <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키>
예)
Select
A.NAME, B.AGE From EX_TABLE A
Left Outer Join JOIN_TABLE B
On A.NO_EMP = B.NO_EMP
And A.NO_DEPT = B.NO_DEPT
3) 풀 아우터 조인(Full Outer Join)
합집합
Select <별칭.칼럼>, <별칭.칼럼> From <기준테이블 별칭> Full Outer Join <조인테이블 별칭> On <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키> And <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키> 예) Select A.NAME, B.AGE From EX_TABLE A Full Outer Join JOIN_TABLE B On A.NO_EMP = B.NO_EMP And A.NO_DEPT = B.NO_DEPT
Select <별칭.칼럼>, <별칭.칼럼> From <기준테이블 별칭>
Full Outer Join <조인테이블 별칭>
On <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키>
And <기존테이블 별칭>.<기준키> = <조인테이블 별칭>.<기준키>
예)
Select
A.NAME, B.AGE From EX_TABLE A
Full Outer Join JOIN_TABLE B
On A.NO_EMP = B.NO_EMP
And A.NO_DEPT = B.NO_DEPT
4) 크로스 조인(Cross Join)
모든 경우의 수(N*M)
Select <별칭.칼럼>, <별칭.칼럼> From <기준테이블 별칭> Cross Join <조인테이블 별칭> 예) Select A.NAME, B.AGE From EX_TABLE A Cross Join JOIN_TABLE B
Select <별칭.칼럼>, <별칭.칼럼> From <기준테이블 별칭>
Cross Join <조인테이블 별칭>
예)
Select
A.NAME, B.AGE From EX_TABLE A
Cross Join JOIN_TABLE B
5) 셀프 조인(Self Join)
하나의 테이블을 여러번 복사해서 조인
Select <별칭.칼럼>, <별칭.칼럼> From <테이블명 별칭1>, <테이블명 별칭2>
Select <별칭.칼럼>, <별칭.칼럼> From <테이블명 별칭1>, <테이블명 별칭2>
데이터베이스 트랜젝션이란?
데이터베이스의 상태를 바꾸는 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들을 의미
모든 명령어의 성공 또는 실패를 한번에 처리 흔한 예로 계좌입금에서 일어날 수 있는 오류등을 생각해보면 좋다.
하나의 트랜잭션으로 관리하면 계좌에 입금하는 기능이 실패 했을 경우, 철수의 계좌에서 돈이 다시 입금되어야한다.(이를 Rollback이라고 한다.)
데이터베이스의 외래키와 무결성 제약 조건
데이터베이스의 외래키
외래키는 두 테이블을 서로 연결하는 데 사용되는 키
외래키가 포함된 테이블을 자식 테이블이라고 하고 외래키 값을 제공하는 테이블을 부모 테이블이라한다.
MySQL: CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), FOREIGN KEY (PersonID) REFERENCES Persons(PersonID) ); SQL Server / Oracle / MS Access: CREATE TABLE Orders ( OrderID int NOT NULL PRIMARY KEY, OrderNumber int NOT NULL, PersonID int FOREIGN KEY REFERENCES Persons(PersonID) );
MySQL:
CREATE TABLE Orders (
OrderID int NOT NULL,
OrderNumber int NOT NULL,
PersonID int,
PRIMARY KEY (OrderID),
FOREIGN KEY (PersonID) REFERENCES Persons(PersonID)
);
SQL Server / Oracle / MS Access:
CREATE TABLE Orders (
OrderID int NOT NULL PRIMARY KEY,
OrderNumber int NOT NULL,
PersonID int FOREIGN KEY REFERENCES Persons(PersonID)
);
무결성의 제약조건
개체 : 테이블에 있는 모든 행들이 유일한 식별자를 가질 것을 요구한다.(같은 값 X)
참조 : 외래키 값은 NULL이거나 참조 테이블의 PK값이여야함
영역 : 한 칼럼에 대해 NULL 허용 여부와 자료형 , 규칙으로 타당한 데이터 값을 지정
HTTP 프로토콜을 이용하게 되는 웹 사이트에서는 웹 페이지에 특정 방문자가 머무르고 있는 동안에 그 방문자의 상태를 지속시키기 위해 쿠키와 세션을 이용한다.
세션
특정 웹사이트에서 사용자가 머무르는 기간 또는 한명의 사용자의 한번의 방문을 의미한다.
세션에 관련된 데이터는 서버에 저장된다.
웹 브라우저의 캐시에 저정되어 브라우저가 닫히거나 서버에서 삭제 시, 사라진다.
쿠키에 비해 보안성이 좋다.
쿠키
사용자 정보를 유지할 수 없다는 HTTP의 한계를 극복 할 수 있는 방법이다.
인터넷 웹 사이트의 방문 기록을 남겨 사용자와 웹 사이트 사이를 매개해주는 정보이다.
쿠키는 인터넷 사용자가 특정 웹서버에 접속할 때, 생성되는 개인 아이디와 비밀번호, 방문한 사이트의 정보를 담은 임시파일로써, 서버가 아닌 클라이언트에 텍스트 파일로 저장되어 다음에 해당 웹서버를 찾을 경우 웹 서버에서는 그가 누구인지 어떤 정보를 주로 찾았는지 등을 파악할 때 사용 된다.
쿠키는 클라이언트 PC에 저장되는 정보이기 때문에, 다른 사용자에 의해서 임의로 변경이 가능하다.(정보유출 가능, 세션 보다 보안성이 낮은 이유)
Get과 Post의 차이점
Get
클라이언트에서 서버로 데이터를 전달할 때, 주소 뒤에 "이름"과 "값"이 결합된 쿼리 스트링 형태로 전달한다.
주소창에 쿼리 스트링이 그대로 보여지기 때문에 보안성이 떨어진다.
길이에 제한이 있다.(전송 데이터에 한계가 있다.)
Post 방식보다 상대적으로 전송 속도가 빠르다.
Post
일정크기 이상의 데이터를 보내야 할 때 사용한다.
서버로 보내기 전에 인코딩하고, 전송 후 서버에는 다시 디코딩 작업을 한다.
주소창에 전송하는 데이터의 정보가 노출 되지 않아 Get방식에 비해 보안성이 높다.
속도가 Get방식보다 느리다.
쿼리 스트링(문자열)데이터 뿐만 아니라, 라디오 버튼, 텍스트박스 같은 객체들의 값도 전송 가능하다.
차이점
Get은 주로 웹 브라우저가 웹 서버에 데이터를 요청 할 때 사용한다.
Post는 웹 브라우저가 웹 서버에 데이터를 전달하기 위 해 사용한다.
Get을 사용하면 웹 브라어저에서 웹서버로 전달되는 데이터가 인코딩 되어 URL에 붙는다.
Post 방식은 전달되는 데이터가 보이지 않는다.
Get 방식은 전달되는 데이터가 255개의 문자를 초과하면 문제가 발생할 수 있다.
웹 서버에 많은 데이터를 전달하기 위해서는 Post방식을 사용하는 것이 바람직하다.
URL Encoding이란?
문자나 특수문자를 웹 서버와 브라우저에서 보편적으로 허용되는 형식으로 변화하는 메커니즘이다.
URL은 ASCII 문자 집합을 사용하여 인터넷을 통해서만 전송할 수 있다.
URL은 종종 ASCII 세트 외부의 문자를 포함하기 때문에 URL은 유효한 ASCII 형식으로 변환되어야 한다.
URL 인코딩은 안전하지 않은 ASCII 문자를 "%" 다음에 두 개의 16진수로 대체한다.
URL은 공백을 포함할 수 없다. URL 인코딩은 일반적으로 공백을 더하기 (+) 기호 또는 % 20으로 바꾼다.
고로, 아스키 이외의 문자는 다 인코딩 해야된다. (한글, 일본어, 중국어, 독일어, ... )
JSON(JavaScript Object Notation)의 약자로 JavaScript에서 객체를 만들 때 사용하는 표현식을 의미한다. 이 표현식은 사람도 이해하기 쉽고 기계도 이해하기 쉬우면서 데이터의 용량이 작다. 이런 이유로 최근에는 JSON이 XML을 대체해서 설정의 저장이나 데이터를 전송등에 많이 사용된다.
라이브러리란 자주 사용되는 로직들을 재활용, 유통 가능하도록 만든 로직들의 묶음을 의미합니다. 자바스크립트의 세계에는 많은 라이브러리들이 있다. prototype, jQuery, YUI 등등 구글트랜드로 검색을 해보면 현재는 jQuery가 가장 많은 사용자를 가지고 있다. jQuery를 이용하면 순수한 자바스크립트로 코딩하는 것 보다 10배 이상 생산성을 높일 수 있다. 또 jQuery는 파생된 라이브러리들을 가지고 있다. jQuery UI는 jQuery기반의 GUI 라이브러리이다. 이것을 이용해서 윈도우 에플리케이션과 같은 기능성의 UI를 만들 수 있다.
최근에는 jQuery Mobile라는 이름의 모바일 라이브러리를 출시해서 모바일용 웹에플리케이션을 만드는데도 많은 도움을 주고 있다.
CSS의 미디어쿼리란?
미디어 쿼리(mediaqueri)는 사이트에 접속하는 장치에 따라 특정한 CSS 스타일을 사용하도록 도와주는 소프트웨어 모듈이다. 미디어 쿼리를 이용한 사이트는 웹 사이트에 접속하는 기기에 따라서 레이아웃이 바뀌게 된다. 즉, PC로 접속하면 모니터 화면에 맞게, 스마트폰으로 접속하면 스마트폰 화면에 맞게 레이아웃이 변경되는 것이다. 웹 문서의 스타일을 정의할 때, 즉 CSS 코드를 작성할 때 미디어쿼리 모듈을 사용해 주는 것이 일반적인 사용 방법이다.
클래스 메소드는 클래스에서 호출되고 인스턴스 메소드가 첫번째 파라미터로 자신의 인스턴스를 self로 전달하는 것과 달리 자신의 클래스를 파라미터로 전달한다. 인스턴스 메소드에서는 인스턴스에 국한하여 데이터를 사용하지만 클래스 메소드는 인스턴스가 공유하는 클래스 데이터를 사용할 수 있다.
class Language: default_language = "English" def __init__(self): self.show = '나의 언어는' + self.default_language @classmethod def class_my_language(cls): return cls() @staticmethod def static_my_language(): return Language() def print_language(self): print(self.show) class KoreanLanguage(Language): default_language = "한국어" >>> from language import * >>> a = KoreanLanguage.static_my_language() >>> b = KoreanLanguage.class_my_language() >>> a.print_language() 나의 언어는English >>> b.print_language() 나의 언어는한국어
class Language:
default_language = "English"
def __init__(self):
self.show = '나의 언어는' + self.default_language
@classmethod
def class_my_language(cls):
return cls()
@staticmethod
def static_my_language():
return Language()
def print_language(self):
print(self.show)
class KoreanLanguage(Language):
default_language = "한국어"
>>> from language import *
>>> a = KoreanLanguage.static_my_language()
>>> b = KoreanLanguage.class_my_language()
>>> a.print_language()
나의 언어는English
>>> b.print_language()
나의 언어는한국어
Docstring란?
Docstring은 코드의 문서화에 도움이 되는 문자열이다. """ 주석 내용 """ 을 사용하여 작성하며 모듈 파일 처음이나 함수, 클래스 선언 다음라인에 주로 작성한다.
return 키워드 대신 yield키워드를 사용하는 함수다. 배열이나 리스트와 같이 반복가능한 값들을 생성해내며 값을 반환할때 모든값을 반환하는 것이 아닌 한 개의 값을 반환한다.
def num_gen(): for i in range(3): yield i g = num_gen() # 제너레이터 객체 생성 num1 = next(g) num2 = next(g) num3 = next(g) print(num1, num2, num3)
def num_gen():
for i in range(3):
yield i
g = num_gen() # 제너레이터 객체 생성
num1 = next(g)
num2 = next(g)
num3 = next(g)
print(num1, num2, num3)
코루틴
제네레이터는 yield를 사용해서 값을 발생시키지만 코루틴은 제네레이터의 무한루프문 안에서 값을 전달받아 사용된다.
while True: # 코루틴을 계속 유지하기 위해 무한 루프 사용 x = (yield) # 코루틴 바깥에서 값을 받아옴, yield를 괄호로 묶어야 함 print(x) co = number_coroutine() next(co) # 코루틴 안의 yield까지 코드 실행(최초 실행) co.send(1) # 코루틴에 숫자 1을 보냄 co.send(2) # 코루틴에 숫자 2을 보냄 co.send(3) # 코루틴에 숫자 3을 보냄
while True: # 코루틴을 계속 유지하기 위해 무한 루프 사용
x = (yield) # 코루틴 바깥에서 값을 받아옴, yield를 괄호로 묶어야 함
print(x)
co = number_coroutine()
next(co) # 코루틴 안의 yield까지 코드 실행(최초 실행)
co.send(1) # 코루틴에 숫자 1을 보냄
co.send(2) # 코루틴에 숫자 2을 보냄
co.send(3) # 코루틴에 숫자 3을 보냄
—
파이썬에서의 메모리 추가/삭제 방법
파이썬은 가비지 컬렉션(Garbage Collection)이 메모리를 관리 해주기 때문에 사용자가 따로 관리할 필요가 없다. 가비지 컬렉션은 객체를 참조하는 다른 객체 또는 위치가 늘어날수록 해당 객체의 reference count는 증감하게 되고, reference count가 0이 되면 객체는 메모리에서 해제하는 식으로 메모리를 관리한다.
가상 머신(Virtual Machine) VS 도커 컨테이너(Docker Container)
기존의 가상화 기술은 가상머신(VM)이라하여 하이퍼바이저를 이용해 여러 개의 운영체제를 하나의 호스트에서 생성해 사용하는 방식이었습니다. 이 때 생성되고 관리되는 운영체제는 게스트 운영체제(Guest OS)라고 하며, 각 게스트 운영체제는 독립된 공간과 시스템 자원을 할당받아 사용합니다. 대표적인 툴로는 virtualBox, VM Ware가 있습니다.
하지만 가상 머신은 게스트 운영체제(Guest OS)를 사용하기 위해 커널과 라이브러리 등이 포함이 되기 때문에 무겁고 용량이 큽니다, 대신에 도커 컨테이너는 가상화 공간을 만들기 위해 리눅스의 자체 기능인 chroot, namespace, cgroup을 사용하기 때문에 성능 손실이 거의 없으며, 컨테이너에 필요한 커널은 호스트 운영체제의 커널을 공유해 사용 하기 때문에, 가볍습니다.
2.인프라 프로비저닝이란?
프로비저닝(Provisioning) 이란 의미는 영어 직역한 그대로 "제공하는것" 이다.
어떤 종류의 서비스든 사용자의 요구에 맞게 시스템 자체를 제공 하는 것을 프로비저닝이라고 하며 제공해줄 수 있는 것은 인프라 자원이나 서비스, 또는 장비가 될 수도 있다.
좀 더 실무적인 표현으로 보자면, IT 인프라 자원을 사용자 또는 비즈니스 Customer에게 Service Vendor 가 제공해주는 것을 말한다.
3. CI/CD
CI(지속적 통합 (Continuous Integration))
- 모든 개발이 끝난 이후에 코드 품질을 관리하는 고전적 방식의 단점을 해소하기 위해 나타난 개념이다. 말 그대로 개발을 하면서 '코드에 대한 통합'을 '지속적'으로 진행함으로써 품질을 유지하자는 것이다.
예시) CI의 자동화가 잘 이루워 졌을 때, 규칙의 단순화 확인
1. 모든 개발자는 퇴근하기 전에 자신의 코드를 중앙 코드와 통합한다.
2. 다음날 출근시 메일로 발송된 결과 리포트를 확인하고 버그가 있으면 수정한다.
CD(지속적 배포(Continuous Deploy 또는 Delivery))
- 소프트웨어가 항상 신뢰 가능한 수준에서 배포 될 수 있도록 관리하자는 개념이다.
-CI가 선행 되어야 CD가 가능하다.
-즉, CI 프로세스를 통해 개발 중에 지속적으로 빌드와 테스트를 진행하고, 이를 통과한 코드에 대하여 테스트서버와 운영서버에 곧바로 그 내용을 내포해 반영하는 것이다. 이상적인 환경이라면 테스트와 빌드가 '지속적'으로 이뤄지기 때문에, 배포 또한 자연스럽게 '지속적'으로 이뤄지게 된다.
CI = 빌드 및 테스트 자동화CD = 배포 자동화
4. git flow
2010년 Vicent Driessen이라는 분이 만든 가장 널리 알려진 Git 작업 절차입니다. Git Flow는master와develop이라는 항상 존재하는 주 브랜치가 있고,feature-*,hotfix-*,release-*라는 필요에 따라 생성하는 브렌치가 있습니다. 물론, 이후improvement-*,bugfix-등 프로젝트에 따라 다양한 브랜치 모델이 추가되기도 하였습니다.
이 절차는 다음과 같은 형태로 진행됩니다.
master브랜치에서develop브랜치를 분기합니다.
개발자들은develop브랜치에 자유롭게 커밋을 합니다.
기능 구현이 있는 경우develop브랜치에서feature-*브랜치를 분기합니다.
배포를 준비하기 위해develop브랜치에서release-*브랜치를 분기합니다.
테스트를 진행하면서 발생하는 버그 수정은release-*브랜치에 직접 반영합니다.
테스트가 완료되면release브랜치를master와develop에 merge합니다.
그리고 이 절차가 반복됩니다.
모니터링 도구란?
모니터링 시스템의 종류
1) 서버 모니터링
서버 여러대중 1대라도 죽는 경우 모니터링 하는것을 말한다.
이를 모니터링하는 도구는 주로 쟈빅스,나기오스, 자체개발 에이젠트 등을 사용한다.
2) 서비스 모니터링
사용자 입장에서 서비스가 안되는 경우 모니터링 하는것을 말한다.
'서비스 전용 모니터링' 도구를 사용한다. Topaz 와 아르고스 등과 같이 사용자단부터 서버까지 모니터링을 하는 툴 이용한다.
어떤 프로세스를 ****커널에 등록****할 것이가를 정하는 ****장기**** 스케줄링,
어떤 프로세스에게 ****메모리를 할당****할 것인가를 정하는 ****중기**** 스케줄링,
어떤 프로세스에게 ****CPU를 할당****할 것인가를 정하는 ****단기**** 스케줄링이 있다.
3. 컨텍스트 스위칭
CPU에서 실행할 프로세스를 교체하는 기술
컨텍스트 스위칭의 순서
컨텍스트 스위칭은 크게 다음과 같은 두 동작으로 구분할 수 있다.
실행 중지할 프로세스 정보를 해당 프로세스의 PCB에 업데이트하여 메인 메모리에 저장
다음 실행할 프로세스 정보를 메인 메모리에 있는 해당 PCB 정보를 CPU에 넣고 실행
PCB 정보 중 PC, SP가 프로세스가 변경된 이후에 작업을 이어나갈 수 있도록 하는 점에서 중요하다.
* PCB : 인쇄회로기판
*스택 프레임 (Stack Frame) : 함수 호출 과정에서 할당되는 메모리 블럭
*스택 포인터 (SP, Stack Pointer) : 현재 스택의 위치 정보를 지니는 포인터. 이 값을 저장하는 레지스터를 sp 레지스터라 한다.
*프레임 포인터 (FP, Frame Pointer) : 함수 호출 종료시 스택 프레임의 반환을 위해 이전 스택 포인터의 정보를 지니는 포인터. 이 값을 저장하는 레지스터를 fp 레지스터라 한다.
4. 가상 메모리
한정된 물리 메모리의 한계를 극복하고자 디스크와 같은 느린 저장장치를 활용해, 애플리케이션들이 더 많은 메모리를 활용할 수 있게 해 주는 것이다.
가상 메모리는 실제 메모리의 남은 공간이 부족하게 되면 사용되는 일종의 임시 공간이다. 그래서 만약 실제 메모리의 용량이 충분하다면 거의 사용되지 않는 특성이 있다. 만약 실제 메모리 공간이 부족하여 가상 메모리가 사용되기 시작하면 위에서 이야기한 것과 같이 [실제 메모리 <-> 가상 메모리] 사이로 데이터를 옮기는 과정들이 추가되기 때문에 그만큼 시스템이 전체적으로 느려지게 된다. 특히나, 실제 메모리 공간인 램에 비해 가상 메모리 공간인 디스크는 매우 느리기 때문에 더더욱 느려지는 것이다.
그래서 가상 메모리는 되도록 사용되지 않을 수록 좋다. 그럴려면 실제 메모리 즉, 램의 용량이 충분해야 한다. 하지만 꼭 메모리 공간이 부족하지 않더라도 일부 프로그램의 경우 반드시 이러한 가상 메모리를 사용하는 경우도 있다.
5. 교착 상태
프로세스가 자원을 사용하기 위해서는 반드시 사용하기 전에 요청 을 해야 하고 사용 후에는 반드시 방출해야 한다. 즉, 정상적은 작동 모드에서 프로세스는 다음 순서로만 자원을 사용할 수 있다.
요청 : 프로세스는 자원을 요청하고, 즉시 허용되지 않는 경우 자원을 얻을 때까지 대기상태에 놓이게 된다.
사용 : 프로세스는 자원에 대해 작업을 수행한다.
방출 : 프로세스가 자원을 다 사용하였다면 방출한다.
이렇게 경쟁 구도에 놓인 프로세스들은 자원을 요청하는 시점에 해당 자원이 다른 프로세스에 의해 점유되어 있으면 대기상태에 놓이게 되고 각 프로세스와 자원들이 서로 꼬리를 물며 자원을 대기하게 되는 경우 이를 교착상태 에 놓여있다고 한다. 즉, 한 프로세스 집합 내 모든 프로세스가 그 집합 내 다른 프로세스에 의해서만 발생될 수 있는 사건을 기다린다면, 그 프로세스 집합은 교착상태 에 있는 것 이다.
외부 사용자(WAN)들이 내부 네트워크(LAN)에 접근하지 못하도록 하는 일종의 내부 네트워크 방어도구이다. 다른 소프트웨어적인 프로그램 도구와는 달리 방화벽이라함은 독립된 시스템이나 전용 하드웨어등을 뜻한다. 연결요청에 대해서 승인된 호스트에 한하여 처리하는 간단한 인증에서부터 패킷필터링 및 분석, 프로토콜 내 특정 공격서명(attack signature)을 막는기술, 사용자 연결의 인증과 암호화 단계까지 다양하게 존재한다.
공격서명(attack signature)이란 해커들이 해킹을 전제로 사용되는 공통되고 비슷한 패턴을 의미합니다. 예를 들어서 80포트를 사용해 텔넷으로 명령을 내린다던지 ftp로 이상한 패킷을 보내는 것과 같은 행위를 말합니다.
인터넷과 인트라넷의 차이점
인터넷
인터넷은 인터넷 프로토콜 제품군 (TCP / IP)을 사용하여 전세계 장치를 연결하는 상호 연결된 컴퓨터 네트워크의 글로벌 시스템
인트라넷
인트라넷은 기업 내에 포함 된 개인 네트워크이다. 상호 연결된 여러 근거리 통신망으로 구성 될 수도 있고 광대역 통신망에서 임대 회선을 사용할 수도 있다. 일반적으로 인트라넷에는 하나 이상의 게이트웨이 컴퓨터를 통한 외부 인터넷 연결이 포함된다.
엑스트라넷
인트라넷과 유사하지만 특정 조직의 인트라넷을 사용이 허가된 사람 이외에도 고객, 협력업체 등에서 사용 할 수 있도록 한다.
인터넷과 인트라넷의 차이점
인터넷은 무엇이든 엑세스 할 수 있는 인터넷이며 개인은 집이나 모바일에서 사용하는 반면, 인트라넷은 회사 또는 조직의 상호 연결된 네트워크이다.
프로토콜이란?
네트워크상 통신회선을 통해서 컴퓨터, 단말기와 같은 시스템 간에 내부적으로 통신, 접속하기 위해 정보, 자료, 메세지 등을 주고 받는 공통의 데이터 교환 방법 및 순서에 대해 정의한 의사고통 약속, 규칙 체계
IPv4(Internet Protocol version 4) : 인터넷 프로토콜의 4번째 판이며, 32비트로 구성된 전 세계적으로 사용된 첫 번째 인터넷 프로토콜이다. 현재 인터넷을 사용하는 장비나 장치들이 늘어 남에 따라 지금은 40억개(232)가 넘는 IPv4의 IP주소가 고갈 되어 2011년 2월 4일 IPv4 주소의 신규할당이 전면 중단 되었다.
IPv6 (Internet Protocol version 6) : 인터넷 프로토콜의 6번째이며, IPv4의 주소가 한계점에 다다르면서 인터넷발전의 문제가 예상되어 IPv6가 제정되었다. IPv6는 128비트의 주소 체계를 가지며 2128개 즉, 340,282,366,920,938,463,463,374,607,431,768,211,456개의 거의 무한대로 쓸 수있다.
TCP와 UDP의 차이점
SSH란?
**시큐어 셸(Secure Shell, SSH)**은 네트워크 상의 다른 컴퓨터에 로그인하거나 원격 시스템에서 명령을 실행하고 다른 시스템으로 파일을 복사할 수 있도록 해 주는 응용 프로그램 또는 그 프로토콜을 가리킨다.
기존의 rsh, 텔넷 등을 대체하기 위해 설계되었으며, 강력한 인증 방법 및 안전하지 못한 네트워크에서 안전하게 통신을 할 수 있는 기능을 제공한다. 기본적으로는 22번 포트를 사용한다.
SSH는 암호화 기법을 사용하기 때문에, 통신이 노출된다고 하더라도 이해할 수 없는 암호화된 문자로 보인다.
- 소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화를 말한다.
- 데브옵스는 소프트웨어 개발조직과 운영 조직간의 상호 의존적 대응이며 조직이 소프트웨어 제품과 서버스를 빠른 시간에 개발 및 배포 하는 것을 목적으로 한다.
-DevOps는 개발(Development)과 운영(Operations)의 합성어입니다
왜 이 두 가지 개념이 합쳐 졌을까요?
서비스의 패치를 위해서 몇 달간의 작업 후 배포하던 고전적인 방식과 달리, 현재는 빈번한 서비스 배포가 주류를 이루고 있습니다. 대부분의 서비스가 설치 기반에서 웹 기반으로 바뀌었으며 마이크로 서비스와 애자일 개발 방법론에 대한 관심이 많아졌고 그로 인해 빈번한 서비스의 배포가 필요해 졌습니다.
하지만 개발팀은 서비스 개발에 매진하고, 운영팀은 보안과 안정적인 인프라 구축에 집중을 하므로 빈번한 배포 전략이 유연하게 동작할 수 없습니다.
이런 새로운 전략을 위해서 두 팀이 병합되어 개발, 테스트, 배포, 운영에 이르는 애플리케이션 수명주기를 개발하게 됩니다.
이를 데브옵스라고 하며, 이는 아래와 같은 이점이 있습니다
DevOps의 이점
속도 배포까지의 빠른 작업속도를 효율적으로 제공하기 때문에 시장 변화에 빠르게 대처하고 비즈니스 성과를 창출 가능.
빠른 배포 새로운 릴리즈와 버그픽스를 빠르게 배포할 수 있으며, 그로 인해 고객의 요구를 빠르게 대응 가능.
안정성 지속적 통합, 지속적 전달, 모니터링, 로깅을 통해 안정적인 서비스 품질을 고객에게 제공 가능.
확장 가능 복잡하거나 변화하는 시스템을 효율적으로 관리 가능.
협업 강화 개발자와 운영팀이 긴밀하게 협력할 수 있기 때문에 책임을 공유하고 워크플로우를 결합할 수 있음. 이를 통해 비효율을 줄이고 시간 절약 가능.
클라우드 기반의 웹서비스를 제공하는 경우 빠른 고객 응대와 배포로 인해서 시장우위를 점할 수 있습니다.
Facebook, Netflix, Flickr같은 회사들은 하루에 10번이 넘는 배포주기를 가지고 있다고 합니다.
뭘해야 하나요?
그럼 저런 이점을 얻기 위해 DevOps는 무엇을 해야 할까요? 위 이미지의 DevOps Flow 구현을 위한 중요한 개념들을 정리해 보았습니다.
SCM (Source Code Management)
우선 팀 단위로 개발되는 소스를 지속적으로 관리해줘야 합니다. 아래와 같은 버전 관리 시스템을 이용해 소스코드 관리를 합니다.
DevOps는 회사의 개발 문화와 밀접하게 연관이 되어 있습니다. 그렇기 때문에 정답이 없으며, 회사 개발 문화에 자연스럽게 녹아드는 DevOps가 최선이라고 생각합니다. 갑작스레 DevOps 전문가를 뽑아서 이렇게 해! 저렇게 해! 한다고 되는 부분이 아니며, 팀 내 개발자들의 관심을 통해 그 서비스의 맞춘 DevOps 환경을 만들어 가야 합니다.
회사에서 DevOps 작업하며 공부한 것들을 작성했으며, 더 많은 내용을 여기에 담으려 했으나! 그러면 매우 길고 지루해질 것 같아 제목에 소개를 붙였습니다. DevOps 관련하여 자동화 배포, 마이크로서비스, 서버패턴, 배포전략 등의 내용을 추가적으로 쓸 예정입니다. 포스트 하나로 때우기에는 생각보다 너무 방대하네요...
상황에 따라서는 AWS에서 관련 서비스를 많이 제공하기 때문에 위에 열거한 툴을 사용하지 않아도 됩니다.
GitLab 자체에서도 CI/CD 도구를 제공하고 있습니다. 회사 동료가 쓰는걸 봤는데 인상적이더군요.
- but 주소를 직접 변경하기 때문에 예외처리를 확실하게 하지않으면 의도치 않게 원본 값이 수정 될 수 있다.
int *p = NULL;
int num = 15;
p = #
2. 컴파일 언어와 인터프리터 언어의 차이점
2-1. 컴파일 언어
- 원시코드->기계어로 변환 후 -> 기계 -> 기계어 코드로 실행
- 소스코드를 기계어로 번역하는 과정에서 인터프리터 언어에 비해 시간이 소요 되지만 런타임 상황에서는 빠르게 실행 할 수 있다.
ex) C, C++
2-2. 인터프리터 언어
- 기계어로 변환하는 과정 없이 한줄씩 해석하여 바로 명령어를 실행하는 언어
- 바로 실행으로 컴파일 언어에 비해 빠르다.
ex) python
3. 컴퓨터의 문자열 처리 방법
표준화된 코드 체계를 사용하여 컴퓨터, 프로그램 간에 데이터를 저장하고 교환할 수 있게 됐다.
-컴퓨터의 기본 저장 단위는 바이트(byte)이다.
-1byte = 8bit
https://whatisthenext.tistory.com/103
-1byte(8bit) -> 256개의 고유값을 저장 할 수 있다.
3-1. 아스키 코드(ASCII)
- 각 문자를 나타내는 7비트와 통신 에러 검출을 확인하기 위한 오류 검사비트 1개를 붙여 총 8비트로 구성
- 128개의 문자를 나타낼 수 있다.
3-2. 유니코드(Uni code)
- 16비트로 구성되어 최대 65,536개까지 표현 할 수 있다.
4.Call by value 와 Call by reference의 차이점
https://codingplus.tistory.com/29
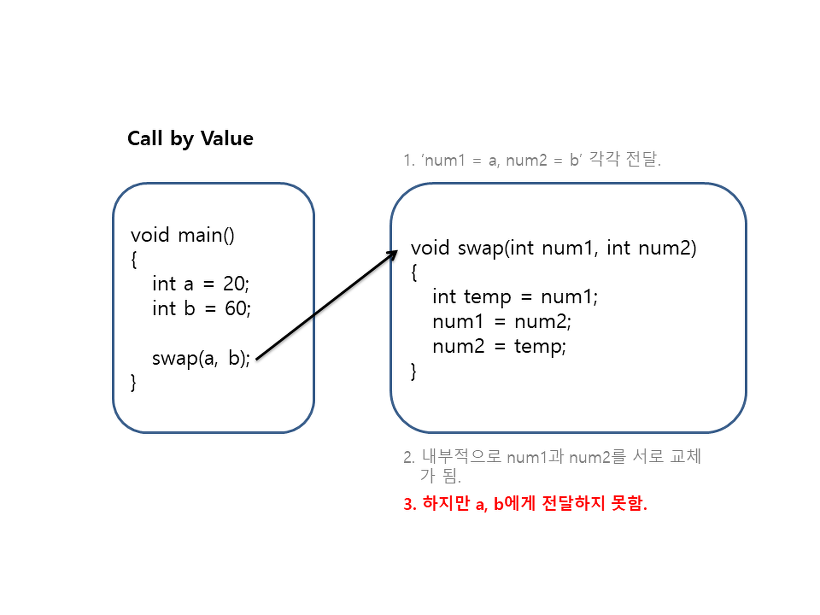
1.Call by value(값에 의한 호출)
- 인자로 받은 값을 복사하여 처리한다.
-장점 : 복사하여 처리하기 때문에 원본 값이 안전하다.
-단점 : 복사하기 때문에 메모리 사용량이 늘어난다.
https://codingplus.tistory.com/29
2.Call by reference(참조에 의한 호출)
- 인자로 받은 값의 주소를 참조하여 직접 값에 영향을 준다.
-장점 : 복사하지 않고 참조하기 때문에 빠르다.
-단점 : 참조하기 때문에 원본 값이 영향을 받는다.
5. 예외처리란?
-에러(error) : 발생 시 수습할 수 없는 심각한 오류
-예외(exception) : 예외 처리를 통해 수습할 수 있는 덜 심각한 오류
프로그램 실행 시 발생할 수 있는 예외에 대비하는 것으로 프로그램 비정상종료를 막고 실행 상태를 유지하는 것
try:
...
except 발생 오류1 as [오류 별칭]:
...
except 발생 오류2 as [오류 별칭]:
...
finally:
...
6. 재귀 함수란?
함수 안에서 함수 자기자신을 호출하는 방식
function factorial(n){
if(n==1){ // 이 조건으로 멈출 수 있다.
return 1;
}
return n * factorial(n-1); //함수 자기 자신을 다시 호출한다.
}
console.log(factorial(5));
7. 클래스와 객체, 인스턴스의 차이점
- 클래스 : 객체를 만들어 내기 위한 설계도 혹은 툴, 연관되어 있는 변수와 메서드의 집합
- 객체 : 클래스를 사용하여 클래스 타입의 객체를 선언
- 인스턴트 : 객체가 메모리에 할당되어 실제 사용될 때
o 붕어빵 틀 = Class o 붕어빵 = 객체(Object) o 붕어빵을 굽다 = 인스턴스(Instance)화 하다 o 만들어진 각각의 붕어빵 = Instance
/* 클래스 */
public class Animal {
...
}
/* 객체와 인스턴스 */
public class Main {
public static void main(String[] args) {
Animal cat, dog; // '객체'
// 인스턴스화
cat = new Animal(); // cat은 Animal 클래스의 '인스턴스'(객체를 메모리에 할당)
dog = new Animal(); // dog은 Animal 클래스의 '인스턴스'(객체를 메모리에 할당)
}
}
중급
1. 메모리 구조에서 스택과 힙의 차이점
http://tcpschool.com/c/c_memory_structure
1.스택(Stack)
- 매개 변수, 지역 변수, 함수(메서드)들이 할당되는 LIFO(Lasr in First Out)방식으로 메모리 사용이 끝나면 바로 소멸되며 컴파일 시메모리에 할당 된다.
- CPU가 스택 메모리를 효율적으로 관리하기 때문에 스택 변수를 읽고 쓰는 속도가 빠르다.
2. 힙(Heap)
- new 연산자를 통한 동적 할당된 객체들이 저장되며, 가비지 컬렉션에 의해 메모리가 관리 되어진다.
- 호출이 끝나도 사라지지 않으며 프로그램 실행시 동적으로 할당된다.
- 힙 메모리는 포인터를 사용하여 힙의 메모리 영역에 접근하기 때문에 읽고 쓰는 속도가 조금 느리다.
2. SW 설계시 의존성 주입, 제어의 역전이란?
1. IoC (Inversion of Control, 제어의 역전)
개발자가 프로그램의 흐름(애플리케이션 코드)을 제어하는 주체였었다. 객체의 생성~ 생명주기 관리를 컨테이너가 도맡아서 하게 된 것이다.
즉, 제어권이 컨테이너로 넘어가게 되고, 이것을 제어권의 흐름이 바뀌었다고 하여 IoC(Inversion of Control : 제어의 역전)이라고 하게 된다.
제어권이 컨테이너로 넘어옴으로써 DI(의존성 주입), AOP(관점 지향 프로그래밍)등이 가능하게 된다.
2. DI (Dependency Injection, 의존성 주입)
각 클래스간의 의존관계를 빈 설정 (Bean Definition) 정보를 바탕으로 컨테이너가 자동으로 연결해주는 것
빈 설정을 개발자가 XML, annotation 방식으로 설정을 하면 컨테이너가 빈의 설정 정보를 읽어서 컨테이너가 자동으로 시켜준다.
3. 다형성이란?
- 여러 가지 데이터를 다룰 수 있는 특성을 뜻 한다.
- 부모클래스의 인스턴스를 이용하여 자식 타입의 클래스를 다룬다거나, 메서드 오버로딩을 통하여 동일 이름의 메서드를 이용하여 다양한 형태의 파라미터를 다루는 것을 뜻한다.
4. 프로세스와 쓰레드의 차이점
1. 프로세스
- 실행중인 프로그램을 나타낸다. CPU가 실행되고 있는 프로세스에 대해 메모리 자원을 안정되게 배분해줘야 하며 운영체제의 성능에 따라 성능이 결정된다.
2. 쓰레드
- 이 프로세스 내에서 실행되는 각각의 일. 프로세스 내에서 실행되는 세부 작업 단위로 여러 개의 스레드가 하나의 프로세스를 이루게 되는 것이다. 스레드는 각자의 스택 메모리영역을 가지고 있으며 동일한 프로세스 내의 다른 스레드들과 전역 메모리를 공유한다. 따라서 CPU로부터 새로운 자원을 할당받지 않아도 되기 때문에 프로세스보다 실행 속도가 빠르다는 장점을 가지고 있다.
5. 자료 구조란?
- 자료(Data)의 집합이며 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 구분하여 표현한 것이다. 자료구조를 잘 선택하는 것으로 실행시간을 단축시켜주거나 메모리 용량의 절약등을 이끌어 낼 수 있다.
- 자료구조는 선형구조와 비선형 구조로 나눠져있다.
선형 구조 : 배열, 링크드리스트, 스택, 큐가 있다.
비선형 구조: 트리, 그래프가 있다.
6. 코드 형상 관리란?
- 코드 형상 관리란 변경사항을 체계적으로 관리하고 제어하기 위한 활동이다. 소스를 버전별로 관리할 수 있어서 개발할 때 실수로 코드를 삭제하거나, 수정하기 이전으로 돌아가야되는 경우 유용하게 사용되며 팀 프로젝트에서 누가 무엇을 어떻게 수정했는지도 알 수 있기 때문에 코드를 병합하거나 수정된 소스를 추적하는 데에도 쓰인다.
형상관리 툴의 종류로는 SVN, CVS, Perforce, ClearCase, TFS, Git 등이 있다.
7. ORM(Object-Relational Mapping)이란?
- ORM은 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것이다.
객체 지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용하는데 이를 맞춰줘서 더 직관적인 코드로 데이터를 조작 및 개발 할수있고 코드의 길이가 줄어든다.
개발하는데 많은 편리성과 이점을 제공하지만 프로젝트의 복잡성이 커지거나 DBMS의 고유 기능을 이용해야될 경우 ORM으로만 서비스를 구현하기가 쉽지않다는 단점이 있다.
book 이라는 객체에서 저자의 이름이 ychaen 인 책 목록을 가져오고 싶을 때,
SQL 쿼리문을 사용할 경우, sql 쿼리문을 작성하고, 데이터를 가져오는 일련의 모든 과정들을 코드에 적어야 한다
book_list = new list();
sql = "SELECT book FROM library WHERE author = 'ychaen'";
data = query(sql);
while (row = data.next()){
book = new Book();
book.setAuthor(row.get('author'));
book_list.add(book);
}
반면 ORM을 사용하면, 간단하게 표현할 수 있다
book_list = BookTable.query(author="ychaen")
고급
1. 알고리즘의 시간복잡도
- 알고리즘의 성능은 시간복잡도와 공간 복잡도로 표현한다.
- 시간복잡도 : 입력밧의 개수와 알고리즘의 처리시간의 상관관계를 표현한 말이다.(입력한 데이터의 양이 많아 짐에 따라 처리 속도가 어떻게 변하는지를 수학의 기호를 빌려 표현하는 방식이다.
-공간복잡도 : 시간복잡도와 동일하나 처리시간 대신 메모리 사용량의 변화를 비교하는 것이 다르다.
- 알고리즘의 성능은 빅오(big-O)표기법 = O(n)표기법으로 표현한다.
2. 임계영역이란?
- 공유되는 자원에서 문제가 발생하지 않도록 독점을 보장해주는 영역이다.
-상호 배제를 통해 다른 프로세스 또는 쓰레드를 대기시켜 문제를 해결할 수 있다
예시) 은행 통장
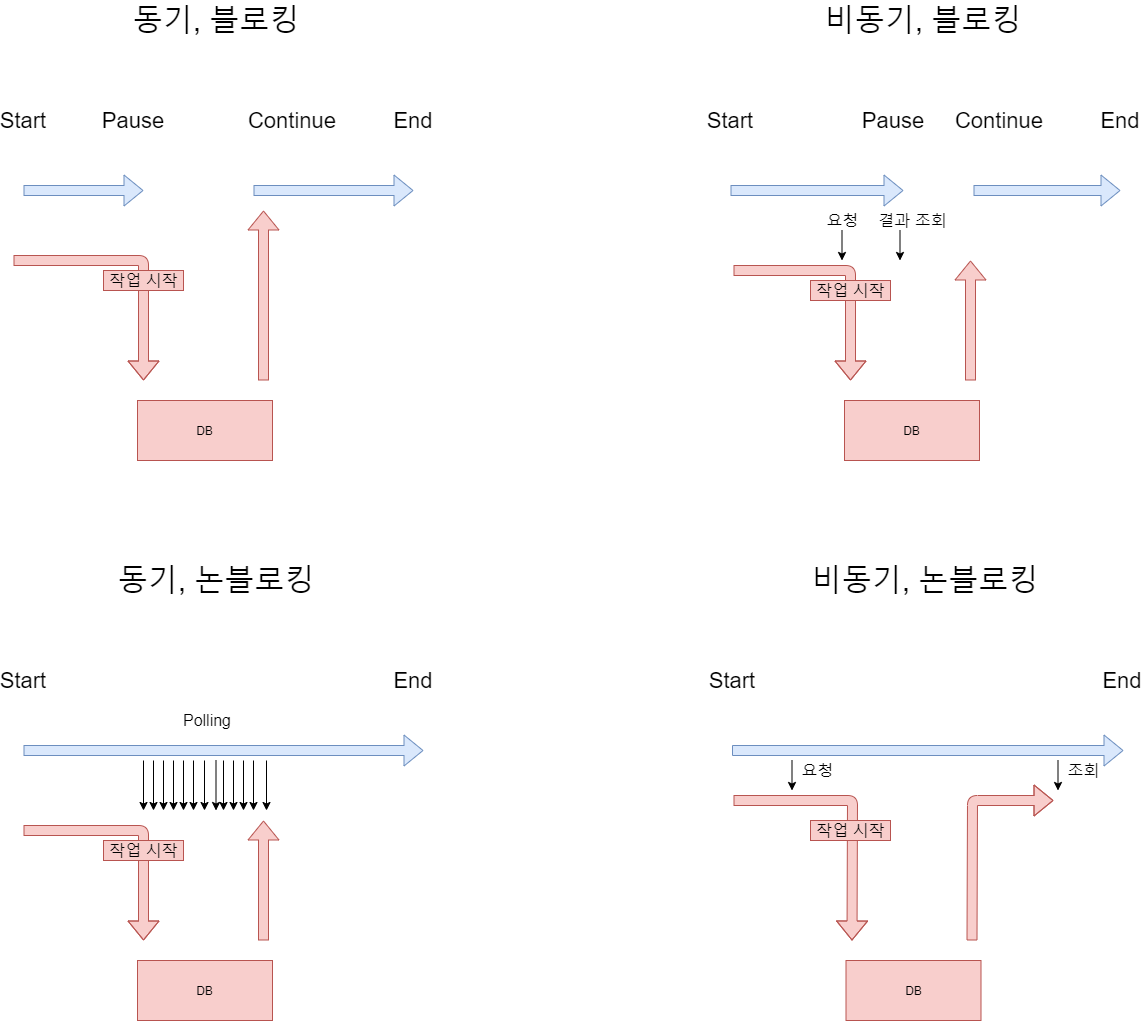
3. 프로그래밍에서 동기와 비동기, 블로킹과 논블로킹의 차이점
"처리시간 차이"
- 동기 : 동시에 일어난다는 뜻, 요청과 그 결과가 동시에 일어난다는 약속, 요청을 하면 시간이 얼마나 걸리던지 요청한 자리에서 결과가 주어진다.
- 장점 : 셀계가 매우 간단하고 직관적이다.
- 단점 : 결과가 주어질 때까지 아무것도 하지 못하고 대기해야한다는 단점
-비동기: 동시에 일어나지 않는다는 뜻, 요청과 결과가 동시에 일어나지 않을 것이라는 약속.
- 장점 : 결과가 주어지는데 시간이 걸리더라도 그 시간동안 다른 작업을 할 수 있으므로 자원을 효율적으로 사용할 수 있다.