RStudio 설치

프로젝트 폴더 설정하기


패키지 설치


프로젝트 실행





























' ctrl + shift + c ' #여러줄 주석
다운로드 사이트 : http://kostat.go.kr/
# 작업 순서
# 1. 데이터 파일 읽기 : 6_101_DT_1B26001_A01_M.csv
# 2. '전국' 지역이 아닌 데이터만 추출
# 3. 행정구역 중 '구' 단위에 해당하는 행 번호 추출
# 4. '구' 지역 데이터 제외
# 5. 순이동 인구수가 0보다 큰지역 추출
# 6. 단어(행정 구역) 할당
# 7. 워드클라우드 출력
# 1. 데이터 파일 읽기 : read.csv(file.choose(), header=T)
# 2. '전국' 지역이 아닌 데이터만 추출('전국' 지역 데이터 제외) : data[data$행정구역.시군구.별 != "전국", ]
# 3. 행정구역 중 '구' 단위에 해당하는 행 번호 추출 : grep("구$", data2$행정구역.시군구.별)
# 4. '구' 지역 데이터 제외 : <- data2[-c(x), ]
# 5. 순이동 인구수가 0보다 큰지역 추출 : data3[data3$순이동.명>0, ]
# 6. 단어(행정 구역) 할당 : data4$행정구역.시군구.별
# 7. 행정구역별 빈도 : data4$순이동.명
# 8. 워드클라우드 출력 : wordcloud()
data <- read.csv(file.choose(), header=T) # 모든 괄호가 .으로 변경된다.
View(data)
head(data)
names(data) # 데이터의 컬럼 확인
# ()가 R에서는 모두 .으로 바뀌어서 들어온다.
data2 <- data[data$행정구역.시군구.별 != "전국", ] # 전체 데이터$컬럼명 중에서 != "전국" 데이터가 아닌 것만 모두 선택
x <- grep("구$", data2$행정구역.시군구.별) # grep함수 : 지정 조건에 맞는 행 번호를 벡터로 반환(x: 구 관련 행번호만 저장)
data3 <- data2[-c(x),] # '구' 지역 데이터 제외
#전입자 수가 많은 지역
data4 <- data3[data3$순이동.명>0, ] # data3중 순이동.명 컬럼 중 0보다 큰애들만 추출
head(data4)
word<- data4$행정구역.시군구.별 # 워드클라우드작업을 위한 글자 데이터만 추출
frequency <- data4$순이동.명 # 숫자값으로 작업할 숫자 데이터만 추
View(frequency)
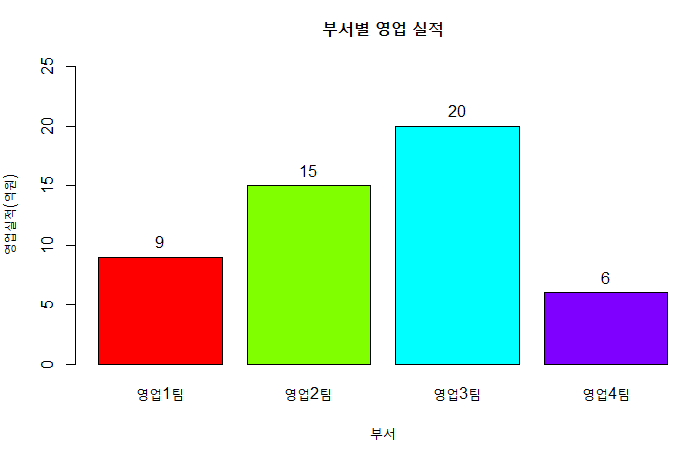
wordcloud(word,frequency,colors = pal2)
#연설문의 단어에 대한 워드 클라우드 만들기
install.packages("KoNLP")
install.packages("RColorBrewer")
install.packages("wordcloud")
library(rJava)
library(KoNLP)
library(RColorBrewer)
library(wordcloud)
KoNLP::useSejongDic()
pal2 <- brewer.pal(8, "Dark2")
text <- readLines(file.choose())#readLines:문서 내부를 엔터 기준으로 줄 단위로 잘읽어드리는 것
noun <- sapply(text, extractNoun, USE.NAMES = F) # extractNoun 이 명사를 찾아서 벡터로 저장하는 역할, sapply는 반환하는 역할
noun
# list 타입의 데이터를 수치형으로 변환
noun2 <- unlist(noun)
noun2
# p.221
word_count <- table(noun2) # 테이블을 하면 팩터로 바꿔준다. # 쪼개진 단어들의 갯수를 파악하여 테이블로 반환
word_count # 단어의 빈도수를 가지고 있음.
head(sort(word_count, decreasing = TRUE), 10) #정렬해주고 상위 10개만 꺼내온다.
wordcloud(names(word_count), # names 라는 함수를 이용해서 단어를 꺼내고
freq=word_count, # freq 옵션을 이용해서 글자나 숫자를 꺼낼 수 있다.
scale=c(6,0.3), # 가장 큰값을 6, 가장 작은 값을 0.3의 비율로 맞춘다.
min.freq=3, # 최소 빈도수를 3 이상으로 잡는다.(1이나 2는 표기하지않는다.)
random.order = F, # 실행할때마다 위치 변경
rot.per = .1, # 회전 각도값을 0.1 비율로 회전시킨다.
colors=pal2) # 글자 색 변경
':: IT > R' 카테고리의 다른 글
| [빅데이터] 전처리 작업, 오라클 연결, xml/json 다루는 방법, Markdown (0) | 2020.04.07 |
|---|---|
| [빅데이터]20200402 데이터 전처리 (0) | 2020.04.06 |
| [빅데이터] 텍스트 마이닝, 등 (0) | 2020.04.03 |
| [빅데이터] 20200401 qplot, 데이터 프레임, 외부데이터 이용, 데이터 수정 및 파악, 파생변수, 조건문, 데이터 전처리, 그래프 그리기 (0) | 2020.04.01 |
| [빅데이터] 20200330 R 정의, 설치, 시각화 (2) | 2020.03.30 |