20200316_판다스(시리즈와 데이터프레임).html
0.32MB
판다스의 기본 구조
#1.R을 모티브로 하여 만든 파이썬 라이브러리
#2.데이터분석을 위해 수집, 전처리 등의 과정은 대부분 데이터프레임의 형태로 이루어진 경우가 많음
#3.데이터프레임 : 행과 열로 이루어진 표, 시리즈가 모여 데이터 프레임
#4.시리즈 : 데이터프레임의 하위 자료형, 1개의 열 시리즈
#파이썬의 엑셀이라고 할 수 있다.
판다스 1. 시리즈
#1. 시리즈
#딕셔너리 만들기
#라이브러리 불러오기
import pandas as pd
#딕셔너리로 시리즈 생성
dict_data = {'a':1,'b':2,'c':3}
series_data = pd.Series(dict_data)
#확인
print(type(series_data))
print('\n')
print(series_data)
print(series_data.index)
print(series_data.values)
#리스트로 만들기
list_data = ['2019-01-02',3.14,'ABC',100,True]
series_data = pd.Series(list_data)
print(series_data)
#인덱스와 값 확인
idx = series_data.index
val = series_data.values
print(idx)
print('\n')
print(val)
#튜플로 만들기
tup_data = ('용근','1995-02-08','남',True)
series_data = pd.Series(tup_data, index = ['이름','생년월일','성별','학생여부'])
print(series_data)
#원소 선택, 인덱싱
tup_data = ('용근','1995-02-08','남',True)
series_data = pd.Series(tup_data, index = ['이름','생년월일','성별','학생여부'])
print(series_data[0])
print(series_data['이름'])
print('\n')
#위치와 이름으로 인덱싱 할 때는 [[]]로 사용
print(series_data[[1,2]])
print('\n')
print(series_data[['생년월일','성별']])
print('\n')
#:로 인덱싱 할때는 []만 사용
print(series_data[1:2])
print('\n')
print(series_data['생년월일':'성별'])
#인덱스 이름으로 사용하면 범위 끝이 포함됨
판다스 2. 데이터프레임
#2.데이터프레임
#시리즈가 여러개 합쳐진 자료형
#딕셔너리로 만들기
import pandas as pd
dict_data = {'c0':[1,2,3],'c1':[4,5,6],'c2':[7,8,9],'c3':[10,11,12],'c4':[13,14,15]}
df = pd.DataFrame(dict_data)
print(type(df))
print('\n')
print(df)

#리스트로 만들기
df = pd.DataFrame([[14,'남','염경중'],[17,'여','양동중']],
index = ['준서','예은'],
columns = ['나이','성별','학교'])
print(df)
print('\n')
print(df.index)
print('\n')
print(df.columns)
# 딕셔너리 : 데이터프레임의 열(column)을 하나씩 쌓아가는 형태
#리스트 : 행(row)을 하나씩 쌓아가는 형태
#행, 열 이름 변경(기본)
df = pd.DataFrame([[14,'남','염경중'],[17,'여','양동중']],
index = ['준서','예은'],
columns = ['나이','성별','학교'])
#df, 모두 인덱스 객체
print(df.index)
print(df.columns)
print('\n')
print(df)
#변경
df.index = ['학생1','학생2']
df.columns = ['연령','남녀','소속']
df

판다스 3. 행, 열 변경
#행, 열 이름 변경 : rename()함수
#1. 데이터프레임 자료형에서 제공하는 함수
#2.df.rename(columns={변경 전 열이름, 변경 후 열이름}, inplace=True)로 사용할 수 있고
#inplace=True옵션을 지정해주면 df에 바로 적용
df = pd.DataFrame([[14,'남','염경중'],[17,'여','양동중']],
index = ['준서','예은'],
columns = ['나이','성별','학교'])
print(df)
print('\n')
#열이름 변경
df.rename(columns={'나이':'연령','성별':'남녀', '학교':'소속'}, inplace=True)
print(df)
print('\n')
#행이름 변경
df.rename(index={'준서':'학생1', '예은':'학생2'}, inplace=True)
print(df)

#행삭제: dorp() 함수
#drop('행 또는 열이름', axis = 0 or 1, inplace =True)
exam_data = {'수학':[90,80,70], '영어':[98,89,95],
'음악':[85,95,100], '체육':[100,90,90]}
df = pd.DataFrame(exam_data, index = ['학생1','학생2','학생3'])
print(df)
print('\n')
#행삭제 : axis=0(디폴트값)
df2 = df.copy() # df[:]로 복사할 시에 판다스는 오류를 반환한다 왜그럴까?
df2.drop('학생2',inplace=True) #행삭제는 axis옵션 생략가능
print(df2)
print('\n')
#열삭제 : axis=1
df3 = df.copy()
df3.drop(['수학','음악'],axis=1,inplace=True)
print(df3)

#데이터프레임 인덱싱 : loc와 iloc
#loc : 이름으로 검색
#iloc : 숫자로 검색
exam_data = {'수학':[90,80,70], '영어':[98,89,95],
'음악':[85,95,100], '체육':[100,90,90]}
df = pd.DataFrame(exam_data, index = ['서준','우현','인아'])
print(df)
#loc : 이름으로 검색
#첫번째 행 서준 선택
label1 = df.loc['서준']
position1 = df.iloc[0]
#데이터프레임으로 보이지만 인덱스명 행 위치로 나타냄
print(label1)
print('\n')
print(position1)
print('\n')
#이제 시리즈 자료형으로 리스트, 튜플, 딕셔너리 형태로 변형 할 수 있다.
print(list(label1))
print('\n')
print(tuple(label1))
print('\n')
#인덱스로 columns명이 자동 부여
print(dict(label1))
print('\n')
#두 개 이상의 행을 선택
label2 = df.loc[['서준','우현']]
position2 = df.iloc[[0,1]]
print(label2)
print('\n')
print(position2)
print('\n')
#열 선택
#df.열이름 or df.['열이름']
exam_data = {'이름':['서준','우현','인아']
,'수학':[90,80,70], '영어':[98,89,95],
'음악':[85,95,100], '체육':[100,90,90]}
df = pd.DataFrame(exam_data)
#수학열 선택
math1 = df['수학']
print(math1)
print(type(math1))
print('\n')
#영어열 선택
english = df.영어
print(english)
print(type(english))
#두개 이상의 열 선택
music_gym = df[['음악','체육']]
print(music_gym)
print(type(music_gym))
print('\n')
math2 = df[['수학']]
print(math2)
print(type(math2))
#범위 슬라이싱
exam_data = {'이름':['서준','우현','인아']
,'수학':[90,80,70], '영어':[98,89,95],
'음악':[85,95,100], '체육':[100,90,90]}
df = pd.DataFrame(exam_data)
df
#iloc : 숫자로 검색
#모든 행을 2행 간격으로 선택
df.iloc[: : 2]
#0행부터 2행까지 2행간격으로 선택
df.iloc[0:3:2]
#역순으로 정렬
df.iloc[: : -1]
#원소선택
#set_index() : 특정열을 인덱스로 부여
#날씨정보의 열, key값을 가진 열을 인덱스로 부여하고 싶은 경우 사용
exam_data = {'이름':['서준','우현','인아']
,'수학':[90,80,70], '영어':[98,89,95],
'음악':[85,95,100], '체육':[100,90,90]}
df = pd.DataFrame(exam_data)
# 이름을 인덱스로 지정
df.set_index('이름', inplace=True)
print(df)
print('\n')
#서준행의 음악열의 값 즉, 원소하나를 가져오는 의미
print(df.loc['서준','음악'])
print('\n')
#서준의 음악, 체육점수를 찾는 4가지 방법
# 1
print(df.loc['서준', ['음악','체육']])
print('\n')
# 2
print(df.loc['서준', '음악':'체육'])
print('\n')
# 3
print(df.iloc[0,[2,3]])
print('\n')
# 4
print(df.iloc[0,2:4])
print('\n')
#두 개 이상의 행과 열을 선택
print(df.loc[['서준','우현'],['음악','체육']])
print('\n')
print(df.loc['서준':'우현','음악':'체육'])
print('\n')
print(df.iloc[[0,1],[2,3]])
print('\n')
print(df.iloc[0:2,2:4])


#행, 열 추가
#열추가 : df['새로운 열이름'] = 값
exam_data = {'이름':['서준','우현','인아']
,'수학':[90,80,70], '영어':[98,89,95],
'음악':[85,95,100], '체육':[100,90,90]}
df = pd.DataFrame(exam_data)
df['국어'] = 80
print(df)
print()
#행추가
exam_data = {'이름':['서준','우현','인아']
,'수학':[90,80,70], '영어':[98,89,95],
'음악':[85,95,100], '체육':[100,90,90]}
df = pd.DataFrame(exam_data)
df.loc[3] = 10
df.loc[4] = ['용근',100,100,100,100]
print(df)
#원소 값 변경하기
exam_data = {'이름':['서준','우현','인아']
,'수학':[90,80,70], '영어':[98,89,95],
'음악':[85,95,100], '체육':[100,90,90]}
df = pd.DataFrame(exam_data)
# 이름을 인덱스로 지정
df.set_index('이름', inplace=True)
print(df)
#변경 4가지 방법
df.iloc[0][3] = 80
print(df)
print('\n')
df.iloc[0,3] = 88
print(df)
print('\n')
df.loc['서준']['체육'] = 90
print(df)
print('\n')
df.loc['서준','체육'] = 100
print(df)
#행과 열 바꾸기
# 전치행렬 : df.transpose(), df.T
df = pd.DataFrame(exam_data)
print(df)
print('\n')
df = df.transpose()
print(df)
print('\n')
df = df.T
print(df)
print('\n')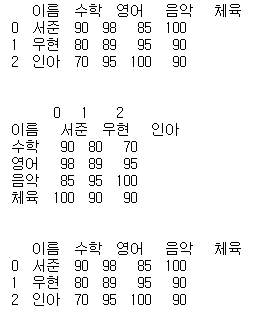
':: IT > python' 카테고리의 다른 글
| 20200316 python 판다스(연산) (0) | 2020.03.20 |
|---|---|
| 20200316 python 판다스(인덱스 정렬) (0) | 2020.03.20 |
| 20200320 python (전처리_시계열데이터) (0) | 2020.03.20 |
| 20200311 python (묘듈, 예외처리, 내장함수, map, 람다) (0) | 2020.03.19 |
| 20200310 python (함수, 사용자 입출력, 파일 읽고 쓰기, 클래스, 상속 ,오버라이딩, 오버로딩) (0) | 2020.03.19 |