hw_0310_.html
0.29MB
20200310 - Jupyter Notebook.pdf
0.62MB
20200310.html
0.34MB
#1.커피머신 프로그램
coffee=10
price =300
# 300 coffee
# 200 반환
# 500 coffee 200 잔돈
# 10잔 소진 종료(더이상 커피가 없습니다.)
while True:
money =int(input("돈을 넣어주세요:"))
if money==300:
print("커피를 줍니다.")
coffee=coffee-1
print('커피가 %d 가 남았습니다' %coffee)
elif money>300:
print("거스름돈 %d를 주고 커피를 줍니다." %(money-300))
coffee=coffee-1
print('커피가 %d 가 남았습니다' %coffee)
else:
print("돈을 다시 돌려주고 커피를 주지 않습니다.")
print('남은 커피의 양은 %d개입니다.' %coffee)
if coffee==0:
print("커피다 다 떨어졌습니다. 판매를 중지합니다.")
break돈을 넣어주세요:100
돈을 다시 돌려주고 커피를 주지 않습니다.
남은 커피의 양은 10개입니다.
돈을 넣어주세요:1235
거스름돈 935를 주고 커피를 줍니다.
커피가 9 가 남았습니다
#함수
#입력값이 없고 결과값만 있는 함수
def say():
return 'hi'
a=say()
say()
# print(a)'hi'
#결과값(return)없는 함수
#print문은 함수의 구성 요소중 하나인 수행할 문장에 해당하는 부분일 뿐임
def sum(a,b):
print('%d,%d의 합은 %d 입니다.' %(a,b,a+b))
sum(3,4)3,4의 합은 7 입니다.
#여러 개의 입력값을 받는 함수 만들기
#*args 처럼 입력 변수명 앞에*을 붙이면 입력값들을 전부 모아서 튜플로 만들어줌
def sum_many(*args):
sum=0 #초기값
for i in args:
# sum+=i 컨트롤 + /
sum=sum+i
return sum
sum_many(1,2,3,4,5)
15
#여러개의 입력값을 받는 함수
def sum_mul(choice,*args):
if choice =='sum':
result=0
for i in args:
result+=i
elif choice=='mul':
result=1 #곱셈은 초기값이 1
for i in args:
result*=i
return result
print(sum_mul('sum',1,2,3,4,5))
print(sum_mul('mul',1,2,3,4,5))15
120
#1.뺄셈 나눗셈 멀티 계산 함수를 작성
#('sub' 2,4,6,8,10)
#('div' 2,4,6,8,10)
def sub_div(choice,*args):
if choice =='sub':
result=100
for i in args:
result-=i
elif choice=='div':
result=100
for i in args:
result/=i
return result
print(sub_div('sub',2,4,6,8,10))
print(sub_div('div',2,4,6,8,10))70
0.026041666666666668
#함수의 반환(결과값)은 언제나 하나임 - 결과값으로 튜플 값 하나를 갖게됨
def sum_and_mul(a,b):
return a+b,a*b
result = sum_and_mul(3,4)
print(result(7, 12)
#하나의 튜플 값을 2개의 결과값처럼 받고 싶다면 다음과 같이 함수를 호출
result1,result2=sum_and_mul(3,4)
print(result1)
print(result2)7 12
#함수는 return문을 만나는 순간 결과 값을 돌려준 다음
#함수를 빠져나가며 두번째 return 문이 실행되지 않음
def sum_and_mul(a,b):
return a+b
return a*b
result=sum_and_mul(2,3)
print(result)
#return은 한번 밖에 쓰지 못한다. 그렇기 때문에 위처럼 result1,result2 를 사용
#하여 2개의 이상의 결과값을 받는다.5
#문자열을 출력한다는 것과 리턴값이 있다는 것은 전혀 다른 말임
def say_nick(nick):
if nick=='바보':
return '아니야!'
print('나의 별명은 %s 입니다' %nick)
say_nick('야호')
say_nick('바보')
나의 별명은 야호 입니다
Out[27]:
'아니야!'
#입력 인수에 초기값 미리 설정하기
def say_myself(name, old, man =True):
print('나의 이름은 %s입니다' %name)
print('나의 나이는 %d살입니다' %old)
if man:
print('남자입니다.')
else:
print('여자입니다.')
# say_myself('홍길동',20) man이라는 변수에는 입력값을 주지 않았지만
# 초기값 true값을 값게된
# say_myself('홍길동',20,true)
say_myself('홍길동',20)나의 이름은 홍길동입니다
나의 나이는 20살입니다
남자입니다.
#초기값을 설정해 놓은 인수 뒤에 초기 값을 설정해 놓지 않은 입력 인수는 사용x
#(name,man=true, old)는 오류를 발생
def say_myself(name, man=True, old):
print('나의 이름은 %s입니다' %name)
print('나의 나이는 %d살입니다' %old)
if man:
print('남자입니다.')
else:
print('여자입니다.')
say_myself('홍길동',20)
#초기값은 항상 끝자리에 와야한다.
#함수 안에서 선언된 변수의 효력범위
a=1
def vartest(a):
a=a+1
print(vartest(a))
print(a)
#리턴값이 없어서 안나옴None
1
#함수 안에서 함수 밖에 변수를 변경하는 방법
#return 을 이용하는 방법
a=1
def vartest(a):
a=a+1
return a
a=vartest(a)
print(a)
#올바른 코딩~2
#글로벌 명령을 이용하는 방법
#글로벌 a 라는 문장은 함수 안에서 함수 밖에 a 변수를 직접사용하겠다는 의미
#함수는 독립적으로 존재하는 것이 좋기 때문에 외부변수에 종속적인 함수는 비추천
a = 1
def vartest():
global a #밖에 있는 a값을 가져옴
a=a+1
vartest()
print(a)
#쓰지마세요~안좋은 코딩
2
#사용자 입력과 출력
a=input()
a501
'501'
number =input('숫자를 입력하세요:')숫자를 입력하세요:5
while 1:
data=input()
if not data: break21
#큰 따옴표로 둘러싸인 문자열은 +연산과 동일함
#문자열 띄어쓰기는 콤마로 함
print("life" "is" "too" "short")
print("life"+"is"+"too"+"short")
print("life", "is", "too", "short")lifeistooshort
lifeistooshort
life is too short
#한줄에 결과값 출력하기
for i in range(10):
print(i,end=' ')
print("\n")
for i in range(10):
print(i)
#파일 읽고 쓰기
f=open('test1.txt','w')#w,r,a수정
f.close()f=open('test1.txt','w')
for i in range(1,11):
data ='%d번째 줄입니다. \n' % i
f.write(data)
f.close()
#쓰기#프로그램의 외부에 저장된 파일을 읽는 방법
f=open('test1.txt','r')
line = f.readline()
print(line)
f.close()
#한줄 읽기1번째 줄입니다.
#readlines 함수는 파일의 모든 줄을 읽어서 각각의 줄을 요소로 갖는 리스트로 돌려준다.
#f.readline()과는 달리 s가 하나 더 붙어 있음에 유의
f=open('test1.txt','r')
lines = f.readlines()
for line in lines:
print(line)
f.close()

# r.read()는 파일의 내용 전체를 문자열로 돌려준다.
f = open('test1.txt', 'r')
data = f.read() # 읽어온걸 data에 저장
print(data) # 입력받은 data를 출력
f.close() # 읽고나면 반드시 클로즈 해줘야 한다
# 파일에 새로운 내용 추가하기
f=open('test1.txt','a') # a는 이미 있는 파일에 내용 추가
for i in range(11, 16):
data = '%d 번째 줄입니다. \n' % i
f.write(data)
f.close()#with문을 사용하면 with block을 벗어나는 순간 객체가 f가 자동으로 close됨
with open('test2.txt','w') as f:
f.write('파이썬은 재미있습니다.')with open('test2.txt','r') as f:
data=f.read()
print(data)파이썬은 재미있습니다.
#class의 필요성
result = 0
def add(num):
global result
result += num
return result
print(add(3))
print(add(4))3
7
#2개의 계산시가 필요한 상황
result1=0
result2=0
def adder1(num):
global result1
result1 += num
return result1
def adder2(num):
global result2
result2 += num
return result2
print(adder1(3))
print(adder1(4))
print(adder2(3))
print(adder2(7))
#이런 중복을 피하기 위해서 클래스를 쓴다.
3
7
3
10
#Calculator클래스로 만들어진
#cal1,cal2라는 별개의 계산기(인스턴스)가 각각의 역할수행
# class를 이용하면 계산기의 개수가 늘어나도 인스턴스를 생성하기만 하면됨
class Calculator:
def __init__(self):
self.result = 0 #기본생성자
def add(self, num):#클래스안에서 정의 할때는 항상 self를 넣는다.
self.result += num #this.result
return self.result
cal1 = Calculator() #cal1만 놓고 봤을 땐 객체, Calculator에서 값이 넣는 것으로 볼 땐 인스턴스
cal2 = Calculator()
print(cal1.add(3))
print(cal1.add(4))
print(cal2.add(3))
print(cal2.add(7))
3
7
3
10
#앞에서 보았던 Calculator클래스에 빼기 기능 추가
class Calculator:
def __init__(self):
self.result = 0
def add(self, num):
self.result += num
return self.result
def sub(self, num):
self.result -= num
return self.result
cal1 = Calculator() #cal1만 놓고 봤을 땐 객체, Calculator에서 값이 넣는 것으로 볼 땐 인스턴스
cal2 = Calculator()
print(cal1.add(3))
print(cal1.add(4))
print(cal1.add(5))
print('\n')
print(cal2.add(3))
print(cal2.add(4))
print(cal2.add(5))
# 사칙연산 클래스 만들기
# 객체에 숫자 지정할 수 있게 만들기
# setdata 메서드에는 self, first, second 총 3개의 매개변수가 필요한데 실제로는
# a.setdata(4, 2) 처럼 2개 값만 전달.
# 이유는 a.setdata(4, 2) 처럼 호출하면 setdata 메서드의 첫 번째 매개변수, self 에는 setdata 메서드를
# 호출한 객체 a 가 자동으로 전달되기 때문임.
# 메서드의 첫 번째 배개변수 self를 명시적으로 구현하는 것은 파이썬만의 독특한 특징
class FourCal:
def setdata(self, first, second): # 메서드의 매개변수
self.first = first #메서드의 수행문
self.second = second #메서드의 수행문
a = FourCal()
a.setdata(4,2)
print(a.first)
print(a.second)
b=FourCal()
b.setdata(3,7)
print(b.first)
print(b.second)4
2
3
7
생성자(Constructor) 란 객체가 생성될 때 자동으로 호출되는 메서드를 의미
파이썬 메서드 이름으로 init를 사용하면 이 메서드는 생성자가 된다.
init 메서드는 setdata메서드와 이름만 다르고 모든게 동일하나 메서드 이름을 init로
했기 때문에 생성자로 인식되어 객체가 생성되는 시점에 자동으로 호출
init 메서드도 다른 메서드와 마찬가지로 첫 번째, 매개변수 self에 생성되는 객체가 자동으로 전달
init 메서드가 호출되면 setdata 메서드를 호출했을 때와 마찬가지로
first와 second 라는 객체변수가 생성
#사칙연산 클래스 만들기
class FourCal:
def __init__(self,first,second): #기본생성자
self.first = first
self.second = second
# def setdata(self,first,second): #데이터를 셋팅시킬 수 있음
# self.first = first
# self.second = second
def add(self):
result = self.first + self.second
return result
def minus(self):
result = self.first - self.second
return result
def mul(self):
result = self.first * self.second
return result
def divide(self):
result = self.first / self.second
return result
class HouseHong:
lastname='홍'
pey = HouseHong()
pes = HouseHong()
print(pey.lastname)
print(pes.lastname)홍
홍
class HouseHong:
lastname = '홍'
def setname(self, name):
self.fullname = self.lastname + name
def travel(self, where):
print('%s,%s여행을 가다' %(self.fullname,where))
pey = HouseHong()
pey.setname('길동')
pey.travel('제주도')홍길동,제주도여행을 가다
#오류 발생은 travel 함수가 self.fullname이라는 변수를 필요로 하기 때문임
pey = HouseHong()
pey.travel('제주도')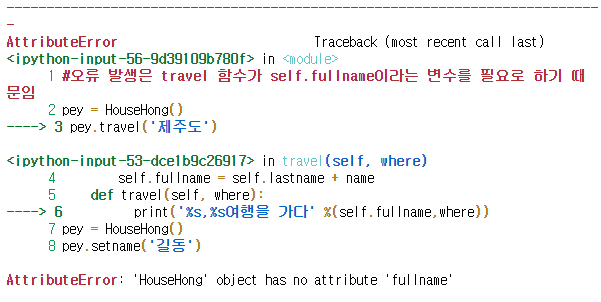
# __init__ 메서드를 이용하면 인스턴스를 만드는 동시에 초기값을 줄 수 있음(중요!!)
#setname은 pey = HouseHong() 객체를 선언하고 값을 넣어주지만
#__init__는 선언 자체만으로 객체선언을 할 필요 없이 값이 들어가게 된다.
class HouseHo:
lastname='호'
def __init__(self, name):
self.fullname = self.lastname + name
def travel(self,where):
print('%s, %s여행을 가다' %(self.fullname, where))
pey = HouseHo('딜런')
pey.travel('제주도')호딜런, 제주도여행을 가다
/*딜러니~~~^^~~*/
class HouseHo:
lastname='우리'
def __init__(self, name):
self.fullname = self.lastname + name
def travel(self,where):
print('%s, %s여행을 가다' %(self.fullname, where))
mr = HouseHo('보비')
mr.travel('제주도')우리보비, 제주도여행을 가다
#클래스의 상속(가져다 쓰고 싶을 때) // 인터페이스= 변수명 항상 반복해서 쓸 때
class HouseOh(HouseHo): #HouseHo는 상속받는 클래스
lastname='오'ys=HouseOh('쵸비')
ys.travel('울릉도')
#윗 클래스를 실행한 후 실행 가능오쵸비, 울릉도여행을 가다
#메서드 오버라이딩(부모클래스의 메소드를 수정하는 것)
# 동일한 이름의 travel함수를 HouseOh 클래스 내에서 다시 구현
# 이렇게 메서드 이름을 동일하게 다시 구현하는 것을 오버라이딩이라고 함
class HouseOh(HouseHo):
lastname='오'
def travel(self,where, day):
print('%s, %s여행을 %s일에 가다' %(self.fullname, where,day))
ch=HouseOh('예쁘니')
ch.travel('서울',3)오예쁘니, 서울여행을 3일에 가다
#연산자 오버로딩()
#연산자를 객체(클래스)끼리 사용할 수 있게 하는 기법
#+연산자를 객체에 사용하면 _add_라는 함수가 호출됨
class HouseLee:
lastname ="이"
def __init__(self,name):
self.fullname=self.lastname+name
def travel(self,where):
print('%s, %s여행을 가다' %(self.fullname, where))
def love(self,other):
print('%s,%s 사랑에 빠졌네'%(self.fullname, other.fullname))
def __add__(self, other): #클래스+클래스 일때 정의하는 것
print('%s,%s 결혼했네'%(self.fullname, other.fullname))
class HouseSung(HouseLee):
lastname='성'
def travel(self, where, day):
print('%s, %s 여행 %d일 가네.' %(self.fullname, where, day))
mr = HouseLee('몽룡')# 객체 클래스 불러오는 것 new
ch = HouseSung('춘향')
ch.travel('이탈리아', 30)
mr.love(ch) #mr의 love에서 ch의 정보를 받는다.
mr + ch #__add__성춘향, 이탈리아 여행 30일 가네.
이몽룡,성춘향 사랑에 빠졌네
이몽룡,성춘향 결혼했네
':: IT > python' 카테고리의 다른 글
| 20200316 python 판다스(pandas) 기초 (시리즈와 데이터프레임) (0) | 2020.03.20 |
|---|---|
| 20200320 python (전처리_시계열데이터) (0) | 2020.03.20 |
| 20200311 python (묘듈, 예외처리, 내장함수, map, 람다) (0) | 2020.03.19 |
| 20200319 python pandas(데이터 전처리) (0) | 2020.03.19 |
| 20200308~20200309 python 기초 (0) | 2020.03.19 |